
Dear readers,
We have received 1,419 papers (829 long and 590 short), from which we sent for review 1,318 papers (751 long and 567 short). We describe how these submissions were processed, and give basic statistics about the submissions. While some of these details are mechanistic and inherently boring, they may be helpful to you when preparing your next submission. At the end of the post, we also add some cool numbers about the submission pool.
Area Assignment: At first, all the papers were assigned to the corresponding areas based on the category you selected during submission. As you have probably noticed, categories in the submission page and our areas have 1:1 correspondence, so this step was straightforward. While most of the papers stayed within their original area, we still had to do significant reshuffling of the submissions. Some of this rerouting has to do with the inherent overlap in area definitions — e.g., semantics/information extraction. Therefore, we wanted to make sure that the papers that addressed similar topics were assessed by the same reviewer pool. In other cases, authors clearly selected an incorrect category. Finding the right home for those papers was a must, to best ensure a good match between interested reviewers and the hard work represented in the submissions.
We implemented this process as follows. Area chairs checked all submissions in their areas, one by one, and recommended papers that they felt did not fit in their area. We also double checked these papers, reassigning them to new areas when needed. In most cases (but not always), we followed recommendations of the area chairs. Overall, around 50 papers were moved from the original areas. This number may not sound like much, but it took many hours of work to complete this process (luckily, MIT was closed during a snow storm on Thursday so I had plenty of time to devote to the task).
Rejection without Review: In parallel, we had to do a really unpleasant task of rejecting papers that violated submission extractions. Some of you have seen the post by EMNLP ’16 chairs Reject without review. Even though I read the post and talked with Xavier and Kevin (EMNLP chairs) in person, I did not realize how painful that process could be. Overall, we rejected close to 70 papers. Examples of such violations include submissions with author names, blatant disregard of ACL templates, and length violations. A number of authors changed ACL templates or did not use them altogether. Depending on the degree of change, we exercised our editorial judgment. While we allowed some, is it really worth it to endanger your submission for a few extra lines? The area chairs made the first review of all papers, and we reviewed all candidates for rejection to ensure consistent policy.
On a personal note, it was a heartbreaking process. Some of these papers looked really good. And I do realize that people who forgot to remove their names from the submission did not do it on purpose. I was particularly concerned that around 30% of papers with violations came from regions which are not typically represented in ACL — rejecting their papers without review does not help them to join the community. I am not sure what could be done for future conferences to change this situation. If you have any thoughts, please share them with us or the ACL exec.
Yet another way to get a paper rejected without review was to submit it to other venues, without declaring it as specified in the submission instructions. Other venues here include journals, arXiv, and other conferences. We got some notifications from area chairs, and continue to receive more during the bidding process.
Mis-channelled Creativity: We had a non-trivial group of submissions that tried to be original in the wrong way. Some of them channeled their creativity into unusual titles such as “dummy”, “delete me”, “wrong paper”, etc. I should notice that these creative titles had little overlap with each other, so one can’t eliminate them with a simple script. The authors in this group also had creative names like Sherlock Holmes (when I saw this masterpiece afters hours of moving papers around, my first thought was Moriarty). For some unknown to me reason, we had several submissions of practically the same papers (repeated up to 3 times in some cases) with name permutations or slight rewrites of the text. In case you are one of the authors in this category, I want to emphasize that our reviewing process is not automated. Most likely, at least three people will have to independently spend time examining such submissions, writing emails about them, and processing the rejection. On hindsight, we will be recommending an operating procedure dealing with such problematic submissions — they bloat the submission pool and cause undue work for the PC.
Last Steps Before Bidding: After all the cleaning and removing duplicates, we obtained 751 long and 567 short papers (roughly, 92% of the originally submitted papers). In parallel, Min and all the ACs were finalizing reviewer assignments for the areas. While we had reasonable estimates for individual areas from previous conferences, the actual submission distribution among areas required us to re-adjust reviewers’ assignments. Again, the process was semi-manual, as we had to arbitrate between reviewer preferences and the needs for each area. By 2 am Friday, we were ready to go, and we started the bidding process. There were some wrinkles during the bidding (Min and I are doing one-shot learning on Smart reviewing systems), but now all seems to be running smoothly. Thank you for your patience and for alerting us about all the issues you experienced!
Now for some interesting statistics.
Procrastination Graph: The first one has to do with the submission time. Many of us submit papers at the last moment. How pervasive is this phenomenon? The graphs below show you the number of submissions as a function of time.
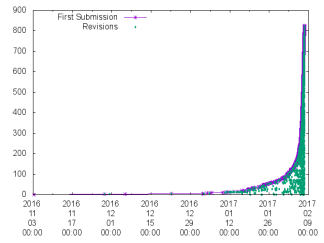
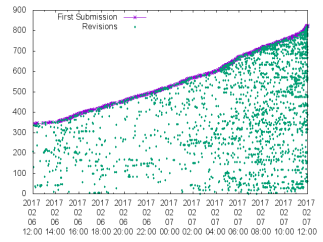
Long paper timestamps of first submissions and revisions: (l) from the opening of the long paper portal, and (r) in the last 24 hours before the official deadline.
Short summary — procrastination (or, stating it positively, desire for perfection) is in the blood of our community. Interestingly, about 24 hours before the deadline, Min was worried about the small number of submissions in the portal — only 342 — it seemed likely we had severely over-recruited reviewers! Not to worry, in 24 hours we were on track.
What’s Hot and What’s Not: 2014 vs 2017 Below we demonstrate top 10 areas ranked by the number of submissions for ACL 2014 and ACL 2017. The chart is interesting: even though the two conferences are just three years apart, we can see a clear shift in popularity — e.g., summarization and generation is now in top 5 areas, while in 2014 it didn’t even make top 10. Check the differences and draw your own conclusions!


Finally, we show statistics for each area, separating the counts for short and long papers. I don’t know how to explain the wide variation in ratios in the table below. (Edit: changed table to add Min’s calculated by area submission projections, as 90% — due to joint short/long deadline — of the average between ACL 2016 and 2014. Negative, red figures are thus signs of unanticipated growth in areas).
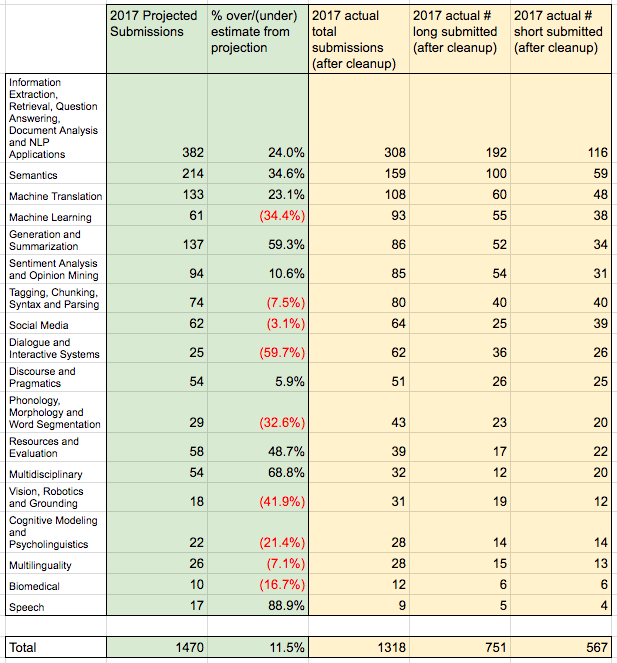
Let us know if you would like us to compute additional statistics!

The procrastination graph doesn’t support the claim. People may have avoided to submit an early version of the paper to avoid problems with resubmission or withdraw. Especially when, this year, the paper withdrawal was unavailable. This issue may easily explain the large number of dummy names such as “delete me” or “wrong paper”.
Best!
LikeLike
Dear Member,
Thank you for your comment. It is indeed hard to know what drove people to submit in the last moment. My conclusions were based on my own group where we typically work until the very last minute to perfect the papers. Many of my colleagues in the US schools observed similar phenomena in their own groups. But of course, my conclusions could be overfitting to the small sample of local observations. The graph is there, and you can draw your own conclusions.
LikeLike
I’d like to hear the rationale behind allowing a submission to be arxiv’d only if it were declared at the submission. Specifically, I’d like to know how this helps anyone including authors, reviewers, area chairs and programme chairs to know in advance whether the submission would be available on arXiv than not knowing it. I could understand why there would be a reason why arXiv’ing would be banned completely (because it would likely hinder with double-blind reviewing?), but cannot see what and how the *declaration* would make any difference.
The declaration of a submission having been submitted to another venue with blind reviewing does make sense, since this declaration is the only way reviewers as well as area chairs could tell whether the submission is considered in another venue. arXiv’ing on the other hand is public, and what role the declaration has is at best questionable (to me).
LikeLike
Dear Kyunghyun,
We had multiple deliberations on how to deal with arXiv publications. The main concern, as you mentioned above, relates to issues with double-blind review. Since reviewers often look at related papers when evaluating the submissions, they may inadvertently find an arXiv submission. By declaring ahead of time arXiv publications, we give reviewers an option of not discovering authors’ identity. We adapted this policy from TACL to increase fairness without imposing a significant burden on the authors.
LikeLiked by 1 person
I understand the concern, but unless a reviewer decides to stop subscribing to arXiv and even closing their eyes and ears to any social media until the decision of a submission with a declaration’s made, I fail to see how it helps in practice.
LikeLike
Are you planning to reviewers to tick a box to declare if they had seen a previous version of this work, as a prepub, or tech report, or PhD thesis, or public/private talk? That info seems (a) more interesting to area chairs and (b) more interesting to do some data analysis on.
LikeLike
I share Kyunghyun’s concerns.
There are several papers submitted to ACL this year which already appear on arXiv — but are not anonymised there.
This poses two problems:
* compromises double-blind reviewing (reviewers may have already seen the paper on arXiv or may find it while searching for related work while reviewing)
* the paper has already been published.
Is there an existing policy on this? We have already rejected papers that were not anonymous, and this is only a small step away. We also ask for unpublished work.
Personally, I always wait until a paper is accepted before uploading to arXiv. It is only a matter of waiting a few weeks, in this case.
I also do not understand the rationale for the current policy, which seems to be that by declaring arXiv submissions ahead of time, this somehow prevents reviewers from finding them (e.g. via google) and therefore observing their authorship.
We need to provide guidance for reviewers on this matter. Personally, I think such submissions violate the important principles of blind reviewing and not being published elsewhere.
LikeLike
I think that ensuring total anonymity is impossible: even if a paper has not been circulated at all, you can often guess the authorship based on the data used or similarity to previous work.
I think anonymous submission is intended primarily to avoid the strong bias that comes with seeing the author names upfront. I felt bad about flagging a non-anonymous paper for rejection because it looked like a good paper — but I can’t tell to what extent my impression of the paper’s quality was swayed by the big name on the title page. This is why we have anonymous submission. If a reviewer finds out the authorship of a paper after having formed an initial opinion, then hopefully the bias is lower.
Reducing reviewer bias is good, but if we take anonymity too far then we’ll end up with policies that stop people from sharing or talking about their results.
LikeLike
Would it be possible to publish statistics on anticipated vs. actual submissions by area? I know Dialogue received more than double the submissions projected based on past ACLs, which caused us to go from an anticipated surplus of reviewers to a serious deficit on the day of submission. It would be interesting to let the community know how other areas fared.
Kudos to the program chairs for moving reviewers between areas in response to the actual submission numbers! You did an awesome job. I have two suggestions going forward:
1. Leave a little more time (an extra day or two) to finalize reviewer-to-area assignment based on actual submission numbers.
2. Try to predict trends better. We, the dialogue area chairs, had a strong suspicion that the projections from past ACLs were producing an underestimate for our area (though we didn’t predict the magnitude). Our suspicion was guided primarily by EMNLP 2016. I know it’s not an easy task, but if we could use additional sources of data to predict trends (for instance other conferences), we may be able to come up with better initial predictions.
LikeLike
Dear Ron,
Thank you for your feedback. I agree with both suggestions. However, as you have seen above, the popularity of areas changes quite a bit between conferences. I am not sure how to make better predictions, but I will be happy to publish statistics about anticipated and actual submissions per area.
LikeLike
Hi Ron, thanks for the idea, and we have (finally) gotten around to computing these statistics. As you surmised, we underestimated certain areas’ popularity, especially Dialogue (which you are helping with as an Area Chair — thanks!). You’ll see these figures in the table above.
LikeLike
Have the authors of “reject without review” papers been notified already?
LikeLike
Dear Yakazimir,
We are in the process of sending these notifications.
LikeLike
We have sent all the notifications for papers identified as violations during the initial screening.
Reviewers found a number of other violations during the review process. Those authors will be notified with the rest at the end of March.
LikeLike
Thanks for the information! About how to help people not to inadvertently violate submission instructions: One possibility would be to include, in the automatic email that confirms that the submission has been received, a warning with a few checkpoints for authors (“IMPORTANT: Please make sure that… / WARNING: papers that don’t… may be rejected without review”). Authors who are not familiar with the procedure (especially anonymizing) may still be able to fix it before the deadline.
Best,
Gemma.
LikeLike
This is a really good idea! I’d encourage future conferences to do this. (When we ran NAACL 2010 we rejected ~5 papers out of hand and some authors were rather upset.)
LikeLiked by 1 person
Totally agree! Great suggestion!
Hal: unfortunately we had to reject many more that 5. I hate it!
LikeLike
Good idea! And another one (both can be implemented at the same time): there could be a list with checkboxes in the submission form, where the author would have to tick the boxes to mark that they have anonymized, respected the space limit, etc. Not ticking a box would result into a red error message telling the author what they need to do.
A more extreme version would have questions where the correct answer is “yes” (“The paper length (minus references) is no more than eight pages”) and others with correct answer “no” (“The first page lists the names of the authors”) to avoid brain-dead clicking, although this might be a bit too much.
LikeLike
> On a personal note, it was a heartbreaking process. Some of these papers looked really good. And I do realize that people who forgot to remove their names from the submission did not do it on purpose. I was particularly concerned that around 30% of papers with violations came from regions which are not typically represented in ACL — rejecting their papers without review does not help them to join the community. I am not sure what could be done for future conferences to change this situation. If you have any thoughts, please share them with us or the ACL exec.
It would be great if there was a way to allow such authors to resubmit a fixed version before it goes to reviewers. Though this may not play well with the reviewing timeline.
I have a lot of sympathy for the issue. For the NLP+CSS workshop last year, we didn’t highlight the fact we wanted ACL paper guidelines and plenty of submissions from social scientists didn’t follow them. We accepted those submissions and asked them to revise for the camera-ready, which they did.
One thing that might help a tiny bit be nice is to streamline submission wherever possible; for example, why do we have that extremely long list of keywords, many of which are very irrelevant? It is newcomer-unfriendly.
LikeLike
Dear Brendan,
Thank you for your thoughtful feedback. Unfortunately, for a conference of the ACL scale, it is impossible to support resubmission after the deadline. However, I do believe we have to provide some automatic checker that can
identify major violations so that the authors have means to spot them before the submission. I also liked suggestions provided by Carlos in the previous comment.
Thanks for bringing up the issue of keywords. I forgot to explicitly say in the blog, but we haven’t used them at all for paper assignment. When we were manually shifting papers across areas, we read abstracts and introduction as they provide much more information for finding the right area. I will suggest future PCs to eliminate keywords all together.
LikeLike
Hi Brendan, all:
Just a small note for the keywords. As Regina pointed out, in our work as PC chairs to assign the papers to areas, they were not used. The keywords, TPMS and reviewer bids all featured in the individual selection and assignment processes that the Area Chairs used to assign reviewers to papers.
Thank you for your thoughtful comments and concerns!
LikeLike
Dear Chairs
I have seen lots of discussions are being made on arXiv and double-blind review policy.
I wonder if uploading the paper on arXiv after the submission but before the notification affects the acceptance of the paper.
Will the paper also be rejected even if it is already under review?
Your reply would be appreciated.
LikeLike
Hi,
This is indeed a violation of the policy. If reviewers see the paper, they have the right to reject it. The notifications are a month away. I will not risk it.
LikeLike
I see.
Again appreciate your reply!
LikeLike